

Hello friends, welcome to new tutorial which is about Parsing HTML in Python using BeautifulSoup4. Today we will discuss about parsing html in python using BeautifulSoup4. Now question arises that, what is HTML parsing?
- It simply means extracting data from a webpage.
Here we will use the package BeautifulSoup4 for parsing HTML in Python.
What is BeautifulSoup4?
- It is a package provided by python library.
- It is used for extracting data from HTML files. Or we can say using it we can perform parsing HTML in Python.
Installing BeautifulSoup4
- Here I am using PyCharm. I recommend you using the same IDE.
- So open PyCharm, Go to file menu and click settings option
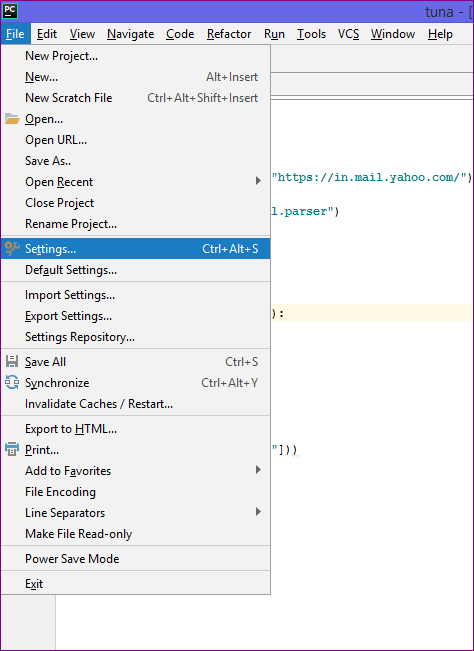
- Click Project Interpreter and press the ‘+’ sign for adding the BeautifulSoup4 package.
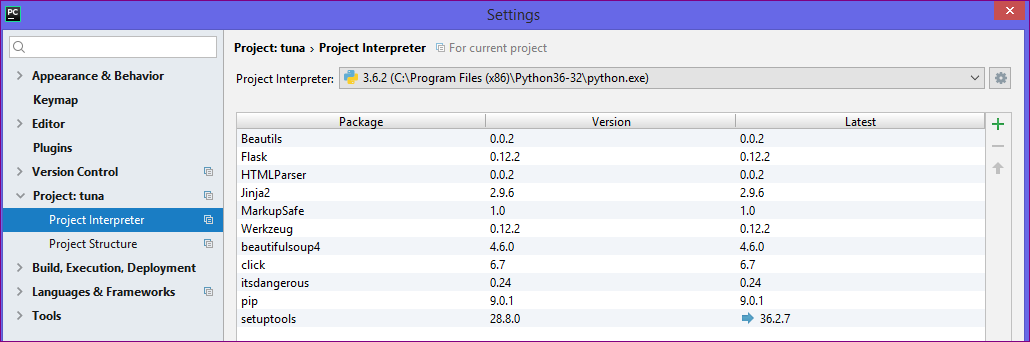
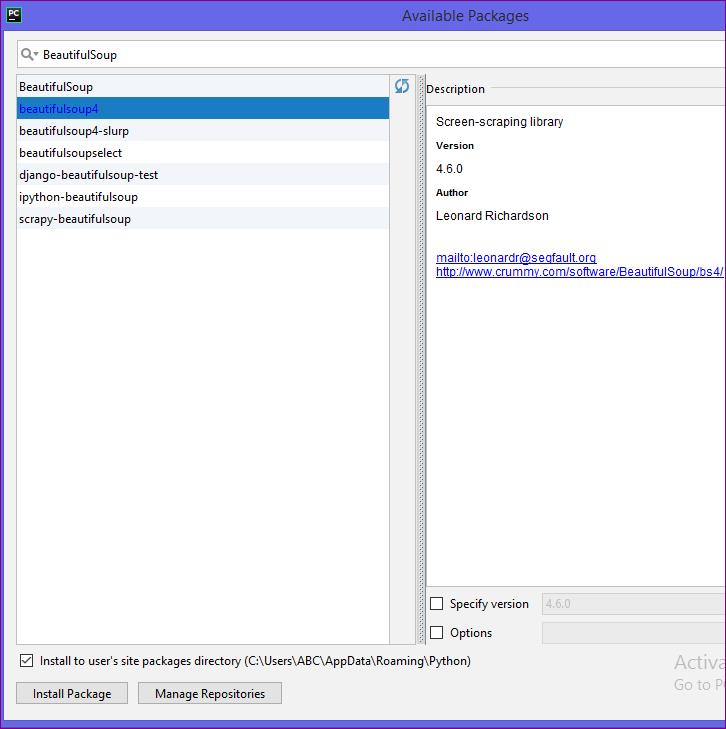
- Select BeautifulSoup4 option and press Install Package.
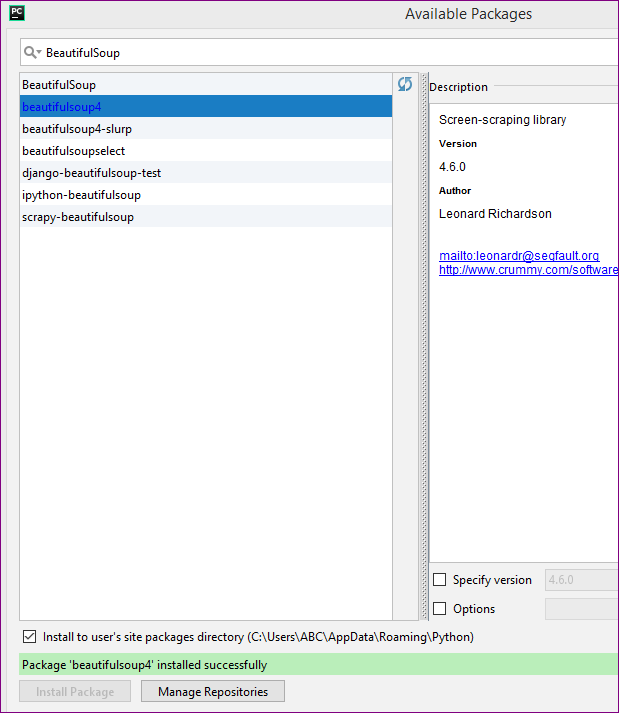
- Now BeautifulSoup4 installed successfully.
Importing BeautifulSoup4
- To use BeautifulSoup4 we need to import it in the code so, Let’s start writing code for importing BeautifulSoup4.
- So inside your IDE create a new Python File and write the first line as below to import BeautifulSoup.
|
1 2 3 |
from bs4 import BeautifulSoup |
Methods of BeautifulSoup4
1. find_all( ):
- This method find all the data within a particular tag which is passed to the find_all( ) method. For example see the following line of code.
|
1 2 3 |
print(html.find_all('script')) |
- The above code will fetch all the script tag from the web page.
Output :
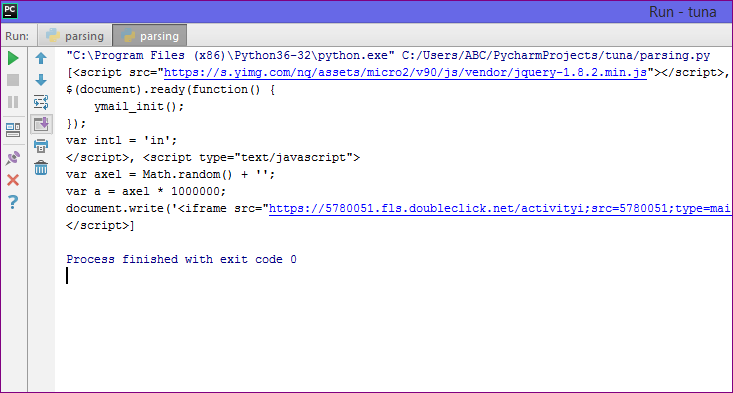
2. prettify( ) :
This method fetch all the HTML contents of a webpage in nice format. So it will basically get the html source code in formatted way so that when we will display it we will see an indented html source.
|
1 2 3 |
print(html.prettify()) |
Above code generates all the html contents available in the Webpage.
Output :
3. get_text( ) :
This method generates only the entire texts of webpage.
|
1 2 3 |
print(html.get_text()) |
Output
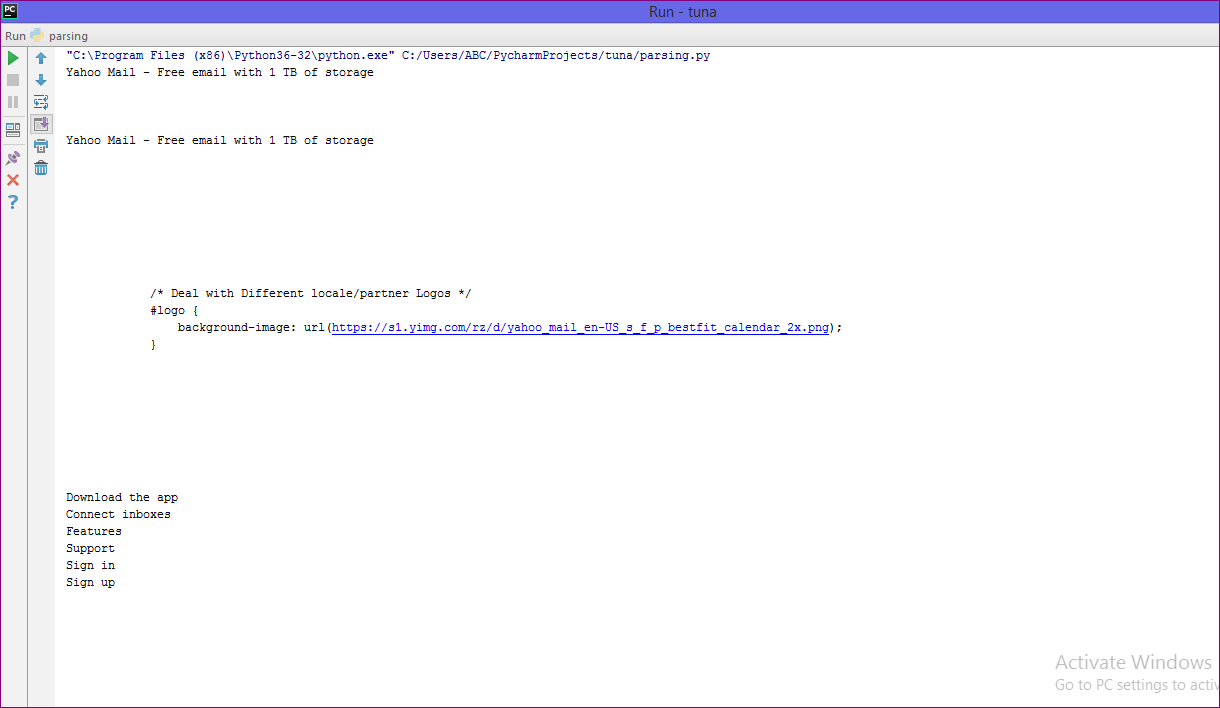
Filters
Following are the filters which are used for generating data from webpage.
1. string :
- pass a string in search method and BeautifulSoup will generate all the contents existed within passed string.
|
1 2 3 |
print(html.find_all('script')) |
- Above code will generate the data which are exist within script tag in webpage.
Output :
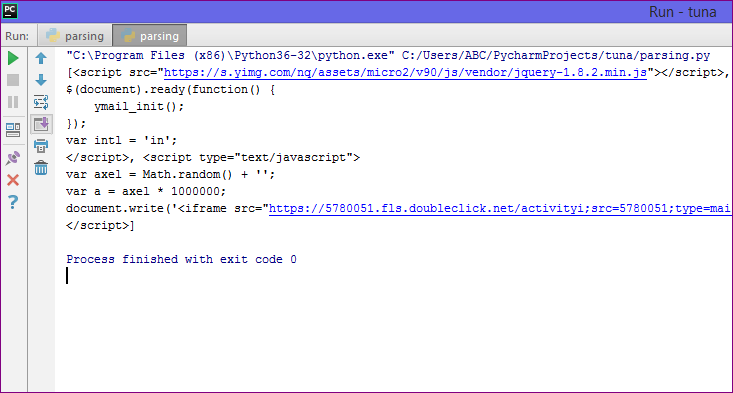
2. True :
- It generates all the tags used in webpage.
- It doesn’t generate the text strings.
|
1 2 3 4 |
for link in html.find_all(True): print(link.name) |
Output :
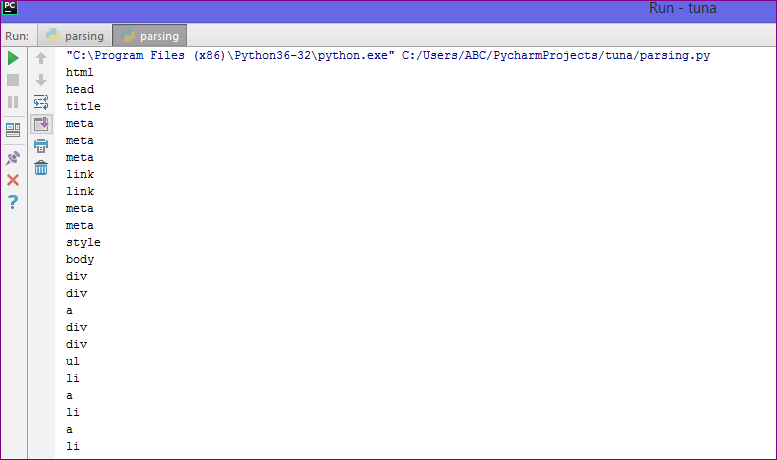
3. list :
- If you pass values in the list , BeautifulSoup will fetch the contents that matches with the list values.
|
1 2 3 |
print(html.find_all(["li", "ul"])) |
- Above code will fetch all li and ul tag present in webpage.
Output :
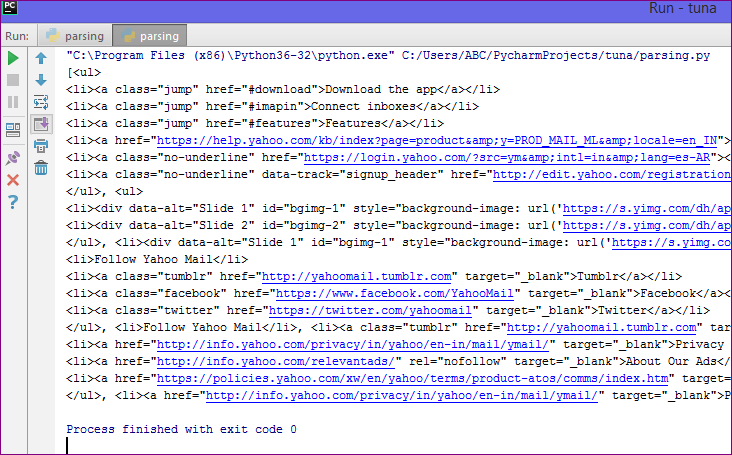
Complete example code for Parsing HTML in Python using BeautifulSoup4
The following code is a complete code for performing parsing html in python using BeautifulSoup4 package
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import urllib.request from bs4 import BeautifulSoup page = urllib.request.urlopen("https://in.mail.yahoo.com/").read() html = BeautifulSoup(page,"html.parser") print(html.title.string) print(html.get_text()) for link in html.find_all(True): print(link.name) print(html.find_all('script')) print(html.prettify()) print(html.find_all(["li", "ul"])) |
Description
- In the first line we import the urllib module.This module is present in python library that provides a high level interface for fetching data from webpages.
- Then In second line we import BeautifulSoup4.
- In the next line we call a function i.e. urlopen( ). This function opens the website as prescribed in url. It takes the data and store them in memory.
- page is just a variable which is declared for storing the data fetched by the urlopen( ) method from the webpage.
- In the next line we call a method BeautifulSoup( ) that takes two arguments one is url and other is “html.parser”. “html.parser” serves as a basis for parsing a text file formatted in HTML. Data called by BeautifulSoup( ) method is stored in a variable html.
- In next line we print the title of webpage.
- Then In next line we call a method get_text( ) that fetches only the entire texts of webpage.
- Furthermore In the next line we call find_all( ) method with an argument True that fetch all tags that are used in webpage.
- In the next line we call find_all(‘script’) method that generates all the contents present within script tag.
- Then in next line we call a method prettify() that fetch all the HTML contents of a webpage in nice format.
- In next line we call print(html.find_all([“li”, “ul”])) that fetch the all li and ul tag present in webpage.
OUTPUT
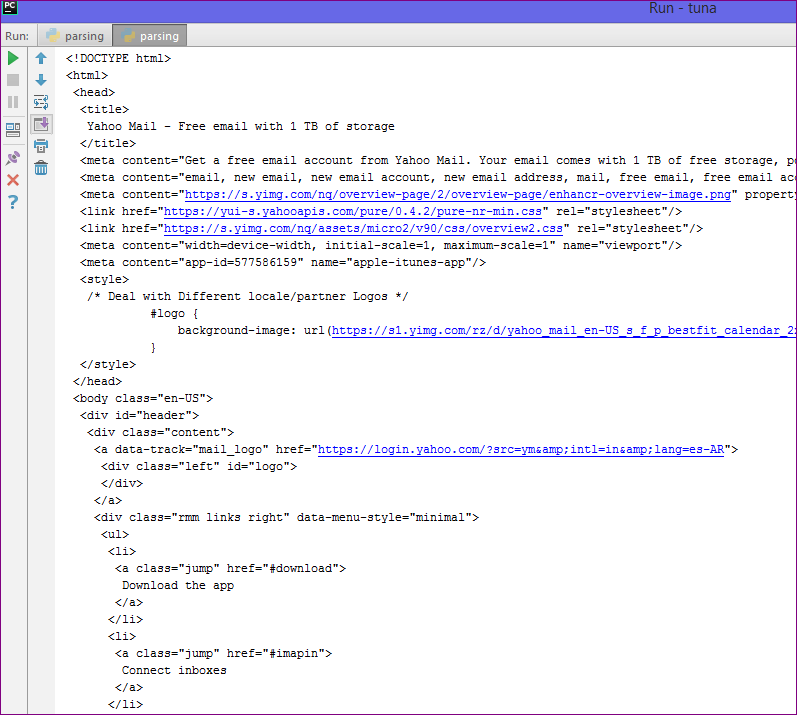
So thats all for this Parsing HTML in Python Tutorial friends. Feel free to leave your comments if you are having any confusions or queries regarding parsing HTML in Python. Thank You 🙂