

Hey everyone, welcome to How To Extract Text From Image In Python tutorial. In this tutorial, you will learn how you can extract text from a image using python. Extracting text from an image can be done with image processing. So let’s see how to do that.
Contents
What Is OCR(Optical Character Recognition) ?
Introduction
- It is a widespread technology to recognise text inside images, such as scanned documents and photos.
- OCR technology is used to convert virtually any kind of images containing written text (typed, handwritten or printed) into machine-readable text data.
How To Implement OCR ?
Now the question arises that how you can implement OCR. Python provides a tool pytesseract for OCR. That is, it will recognize and “read” the text embedded in images.
What Is pytesseract ?
- pytesseract will recognize and read the text present in images.
- It can read all image types — png, jpeg, gif, tiff, bmp etc. It’s widely used to process everything from scanned documents.
Installing pytesseract
To install pytesseract, you have to run the following command in your terminal.
|
1 2 3 |
pip install pytesseract |
How To Extract Text From Image In Python
So now we will see how can we implement the program.
Downloading and Installing Tesseract
The first thing you need to do is to download and install tesseract on your system. Tesseract is a popular OCR engine.
- Download tesseract from this link.
- And install this as usual as you install other softwares.
Creating New Project
Now create your project as usual. In my case, my project is like that –
Python Program For How To Extract Text From Image
This is our image, and we want to extract texts from this image.

So guys now write the following code to extract texts from above image. I will explain it later.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# Import modules from PIL import Image import pytesseract # Include tesseract executable in your path pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe" # Create an image object of PIL library image = Image.open('F:/imagess.jpg') # pass image into pytesseract module # pytesseract is trained in many languages image_to_text = pytesseract.image_to_string(image, lang='eng') # Print the text print(image_to_text) |
Explanation
- First of all you have to import Image class from PIL(Python Imaging Library) library. PIL is short form of Pillow and this is the name used for importing the library.
- Image class is required so that we can load our input image from disk in PIL format.
- Then import pytesseract.
- Now you have to include tesseract executable in your path.
- Then you will need to create an image object of PIL library.
- Now you have to pass that image into pytesseract module.
- image_to_string returns the result of a Tesseract OCR run on the image to string.
- Then finally print the text.
Output
Now run the above code and check the output.
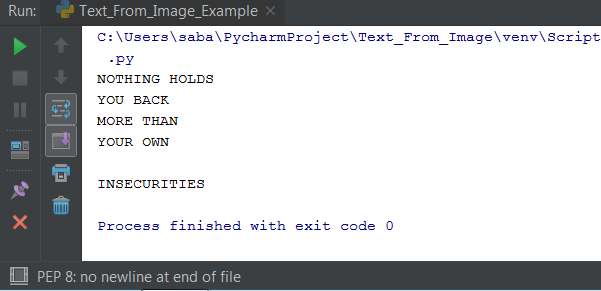
So guys, you can see the code is working successfully. Texts have been extracted from the image.
So this was all about How To Extract Text From Image In Python tutorial. I hope, you will have learned lots of thing from it. But anyway if you have any confusion regarding this tutorial then feel free to ask. And please share it your friends and python learners. Thanks Everybody.
Related Articles :
- Convert Python To exe Tutorial
- Python JSON Pretty Print – JSON Formatting with Python
- Reverse A List Python – Reverse A List With Examples
- Python Split String By Character – Split String Using split() method
my image is not extracting at 100%..some part missing from original image.i have tried for 3 different images.