

Welcome to Wikipedia API Python tutorial. In this tutorial we will learn scrapping wikipedia data using python. Web scrapping is a very useful task in web development. Many applications require it, so let’s start learning it. I have already uploaded a post about web scrapping ,you can check it first.
Parsing HTML in Python using BeautifulSoup4 Tutorial
What Is Wikipedia API ?
Before going further we will discuss a little bit about Wikipedia API.
- Python provide a module Wikipedia API that is used to extract wikipedia data.
- The main goal of Wikipedia-API is to provide simple and easy to use API for retrieving informations from Wikipedia.
- It supports many operations like extracting text, links, contents, summaries etc from wikipedia.

Wikipedia API Python – Scrapping Wikipedia Data
python provides a most popular module wikipedia. By using this module we can extract data from wikipedia. So now i am going to explain how to scrap wikipedia’s data and it’s various ways to scrap data.
Installing wikipedia-api Module
For installing wikipedia module, we have to go on terminal and run the following command –
|
1 2 3 |
pip install wikipedia |
Finally our module has been installed successfully. Now let’s start extracting data from wikipedia.
Create A New Project
Open your python IDE and create a new project and inside this project create a python file. If you are confused about which IDE is best then this link is helpful for you. So in my case my project is like that –
And now we will start extracting data so let’s see how to do them ?
Extracting Summary Of An Article
If you want to extract summary of an article on wikipedia then you have to write the following code.
|
1 2 3 4 5 |
import wikipedia print(wikipedia.summary("google")) |
- First of all import wikipedia this will help to call the method of wikipedia module.
- summary() is used to extract the summary of an article.
- Here i am extracting the summary of google on wikipedia. Whatever webpage you want to extract just pass them as parameter to summary() method.
And now you can see the output –

It printed the whole summary but if you want to extract only 2 or 3 sentences or as you wish then you can do so just passing an argument as like below.
|
1 2 3 |
print(wikipedia.summary("google", sentences=2)) |
This will give you output as below and you can see clearly that it printed only 2 sentences of google’s summary.

Also Read: Python Rest API Example using Bottle Framework
Extracting Search Titles Of The Article
Now, if you want to get the search title of a page that means what are the related searching keyword of a page. For example if you search for facebook that will give all the related keywords of facebook page. So the code for this is –
|
1 2 3 4 5 |
import wikipedia print(wikipedia.search("facebook")) |
- search() method will return you a list of all related search.
- Here i am searching for facebook, so let’s see what are the related searches of facebook.
- In the below output we see the related searches for facebook are Facebook Messenger, Facebook Stories etc.

Changing Language Of An Article
You can also change language of the article. You can change it in any language like Hindi, Tamil , German, Spanish etc. For this you have to write the following code.
|
1 2 3 4 5 6 7 |
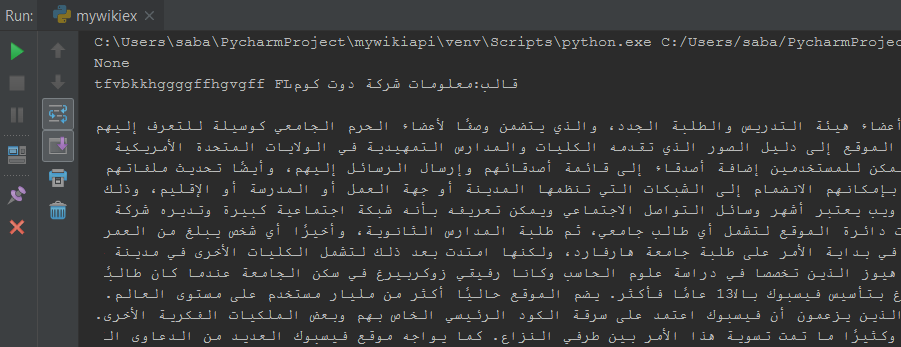
import wikipedia print(wikipedia.set_lang("ar")) print(wikipedia.summary("facebook")) |
- set_lang() method is used to set the language that you want to set.It takes an argument that is prefix of the language like for arabic prefix is ar and so on.
- If you want to know about the prefix of the different languages then refer this link but make sure that the Wikipedia should have that article in the language you want.
- Here i have set the language arabic and article is facebook.It will give the summary of facebook in arabic language that’s so amazing.
Getting Suggestion From Search
Now if you want to get suggestion for what you are searching. For example if you are searching facebook and you are entering facebook as facebok or any thing else. For this purpose we have a method suggest() that makes an intelligent guess on what you are searching and return result. So let’s see how it can be implemented ?
|
1 2 3 4 5 |
import wikipedia print(wikipedia.suggest("faceook")) |
- Here i am entering the parameter faceook and this will give you a suggestion. Now lets see what suggestion it will give.
Bingo it is suggesting as facebook.
Extracting Complete Content Of A Page
If you want to get complete content from a page on wikipedia then you have to use page() method. It returns you an object that has all necessary function like image_link, content, categories, page_id etc. The code for this is –
|
1 2 3 4 5 6 |
import wikipedia complete_content = wikipedia.page("facebook") print(complete_content.content) |
- First of all wikipedia.page() will store all the relevant informations from the requested page in the variable complete_content.
- Then we have to use the content property that will print the entire content from start to end of a page on the screen like below.
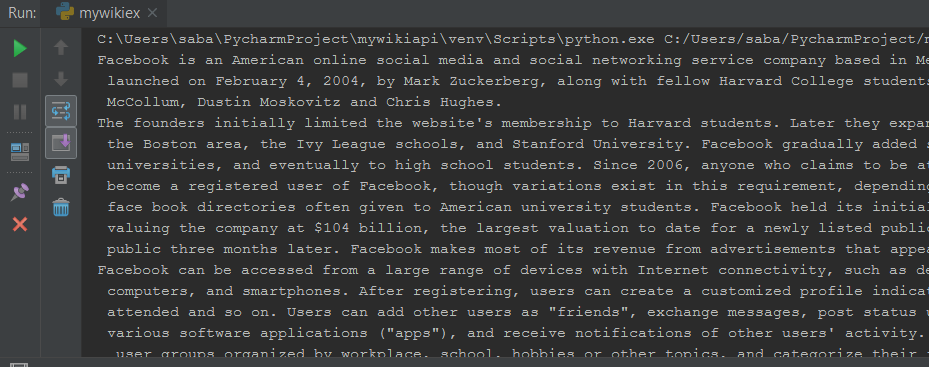
So you can see the output as it has printed the entire content but here i can show you only that much part because i can’t take screenshot of entire output.
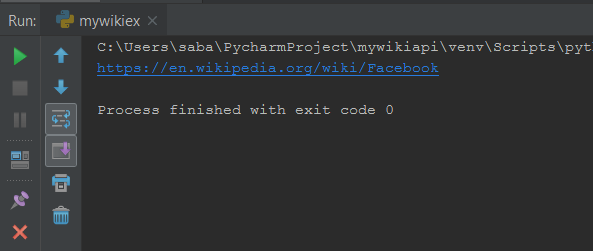
Getting URL Of A Page
Now getting an URL of a page is pretty easy.For this you have to write the following code –
|
1 2 3 4 5 6 |
import wikipedia complete_url = wikipedia.page("facebook") print(complete_url.url) |
- Here i am extracting the URL of facebook page so i have entered facebook as a parameter to page() function.
- Then you have to use the url property that will give you the URL of the page that you have entered.
So the output is –
Extracting Images Included In A Page
And now if you want to extract images from a page on wikipedia, you can do so by writing following chunks of codes.
|
1 2 3 4 5 6 |
import wikipedia page_image = wikipedia.page("India") print(page_image.images[0]) |
- Here i am passing India as an argument.
- page_image.images[0] will return the URL of the image that is present at index 0. If you want to fetch another image use index as 1, 2, 3, etc, according to images present in the page.
- So the output of this code will be –

You can see the image by just clicking on this url.
Downloading Images From A Page
You can also download the image to your local directory. For this we use urllib. urllib is basically a Python module that can be used for opening URLs. It defines functions and classes to help in URL actions. So the code for downloading image is –
|
1 2 3 4 5 6 7 8 9 |
import urllib.request import wikipedia page_image = wikipedia.page("facebook") image_down_link = page_image.images[1] urllib.request.urlretrieve(image_down_link , "loc.jpg") |
- urllib.request module defines functions and classes which help in opening URLs (mostly HTTP) in a complex world — basic and digest authentication, redirections, cookies and more.
- urllib.request.urlretrieve() will retrieve the image of index 1. It takes two parameters one is the image link and another is the name of image as the name we want to save. Here we gave the image name as loc.jpg .
- This image will be downloaded in the same directory where our program is saved.
And now we can see that our image is downloaded successfully and the name is loc.jpg .
And the downloaded image i.e., the image of index 1 on facebook page is as below –

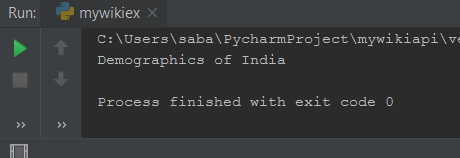
Extracting The Title Of Page
To extract the title of any page on wikipedia we have to write the following code.
|
1 2 3 4 5 6 |
import wikipedia page_Title = wikipedia.page("Indian Demographic") print(page_Title.title) |
- Here i am extracting title of Indian Demographic.
- title property is used to get the title of a page.
So now let’s see what is the result –
So guys, this was all about Wikipedia API Python Tutorial. And now if you have any query then leave your comment. And please share this post as much as possible. Thanks every one.
thanks for this post really it was great for grab more data for machine learning dataset..
thanks so much